





{kind=link}
Introduction
This article discusses Git and demonstrates an example of a typical incorrect configuration.
General Information
When working with Git, upon writing ‘git push,’ it automatically sends all changes made in your project directory to the Git repository.
However, sometimes developers don’t want all files to be sent to the repository because some of them might contain sensitive data, such as login credentials, or perhaps a file is too large to be sent or unnecessary in the repository. In such cases, developers use .gitignore to prevent Git from tracking changes in these files or directories.
How it works: a developer creates a text file named .gitignore (without an extension) saved in the root of the repository. Each line in .gitignore is a pattern for files or directories they don’t want to send to the repository. Yet, the absence of proper protection for such a file can lead to serious problems for a company or organization.
Detecting this issue
If file and directory enumeration tools are permitted, you can use dirsearch or any other tool with a reliable word list.
But if automated tools aren’t allowed, you can simply navigate to https://example.com/.gitignore or similar paths like .git/config, .git/HEAD, .git/logs/HEAD, .git/index.
The following screenshot shows an example of a publicly accessible .gitignore.
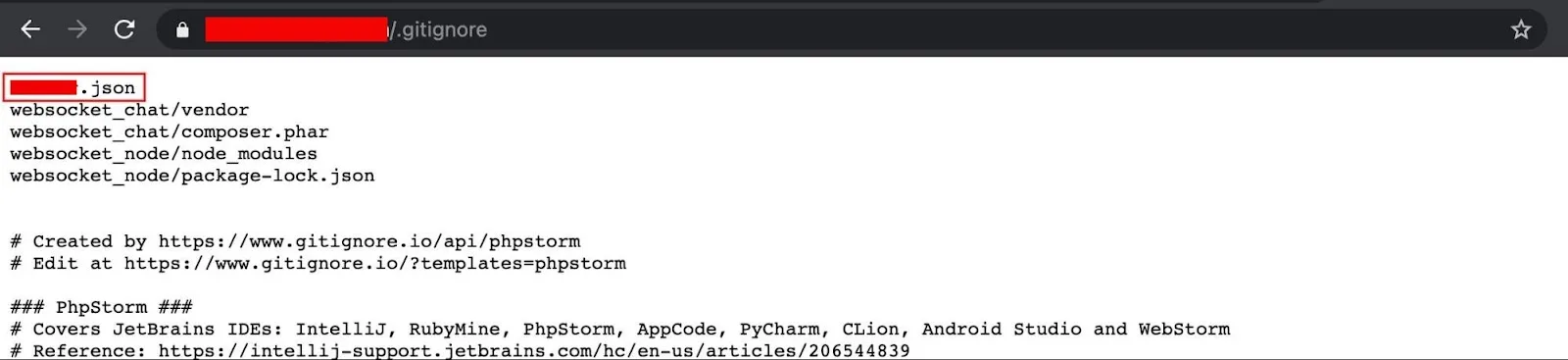
Analyzing paths and delving into files, I discovered a JSON file containing detailed login credentials for accessing the MySQL database.
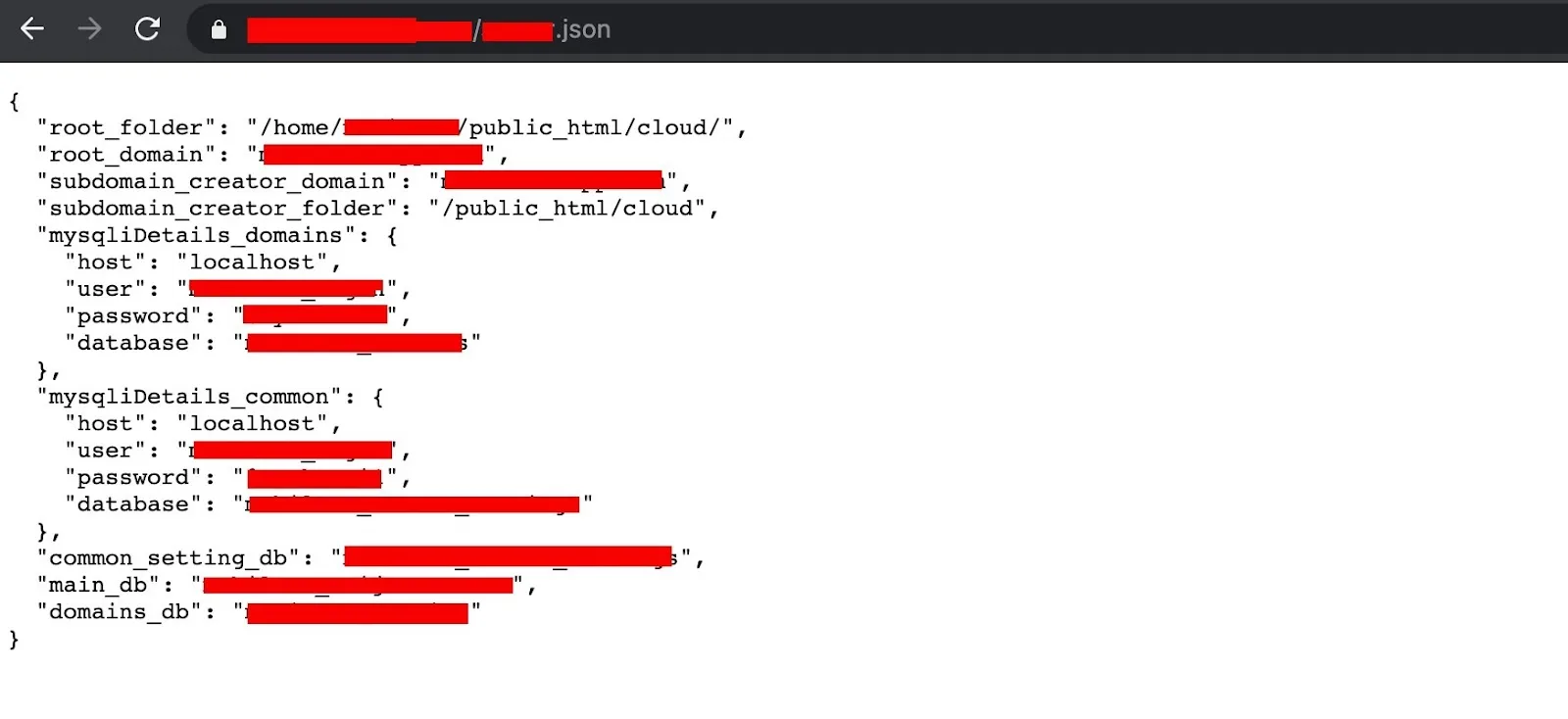
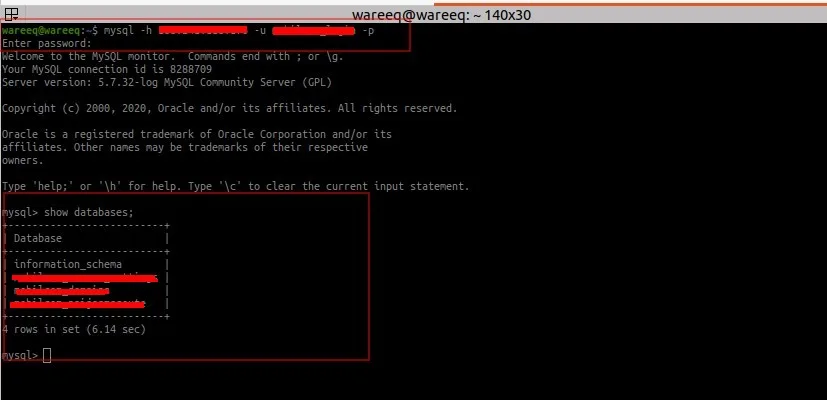
Remote connection to MySQL was enabled, and I was able to access the database using these credentials.
Fixing the Issue
Rectifying the problem was rather straightforward; it simply required changing the file’s access permissions and ensuring it wasn’t publicly accessible.
Conclusion
Often, an application’s hidden content becomes accessible due to human error, negatively impacting system or organizational security. For similar reasons, I recommend dedicating more time to reconnaissance and exploring various endpoints of a website for a better understanding of its purpose and to uncover interesting areas.
thx
essential stuff